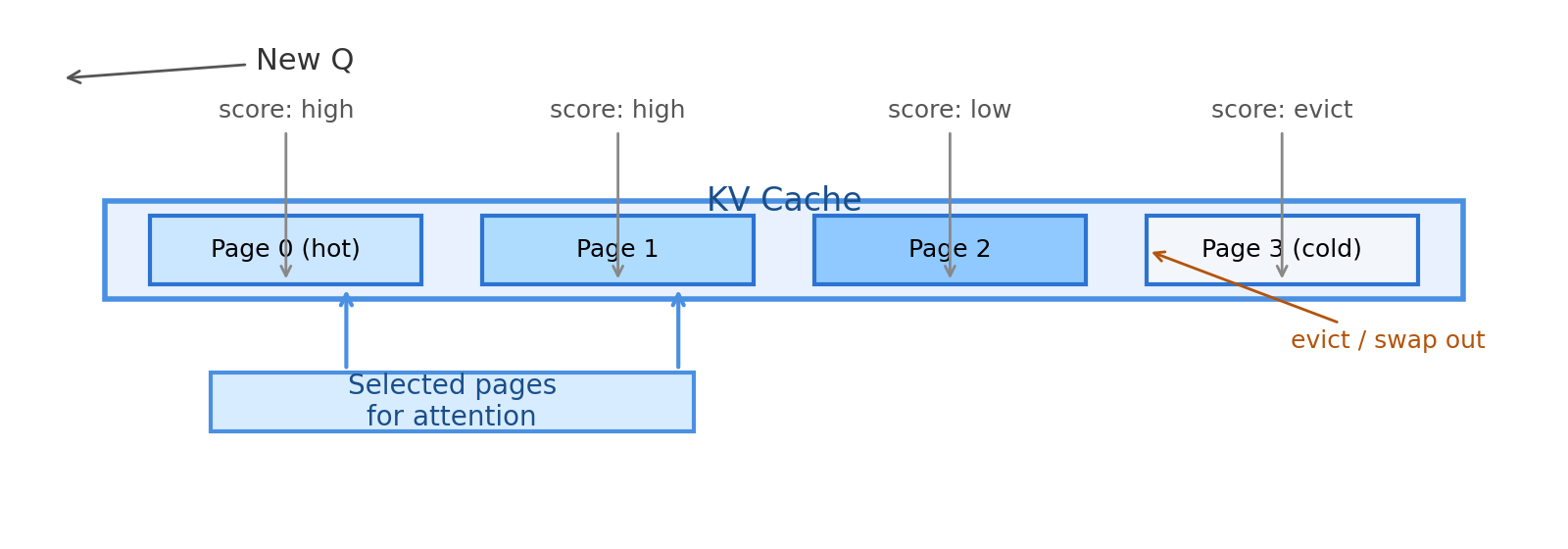
### Paged Attention Demo(视频) <video src="https://cdn-uploads.huggingface.co/production/uploads/6527e89a8808d80ccff88b7a/DP2zDJTAU-yHrxVRh5GUt.mp4" controls width="100%" poster="../images/2025/l12/paged_attention.png"> Your browser does not support the video tag. </video> (注:此视频仅在 HTML 播放,PDF/PNG 导出不支持播放) ---