第3讲: 深度学习基础 II
深度学习模型三要素
“搞模型如同炒菜,食材、大厨、锅,缺一不可”
class LeNet(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*4*4, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
forward方法
def forward(self, x): x = nn.functional.relu(self.conv1(x)) x = nn.functional.max_pool2d(x, 2, 2) x = nn.functional.relu(self.conv2(x)) x = nn.functional.max_pool2d(x, 2, 2) x = x.view(-1, 16*4*4) x = nn.functional.relu(self.fc1(x)) x = nn.functional.relu(self.fc2(x)) x = self.fc3(x) return x
闪回模型的层
nn.Linear(input, output)
linear = nn.Linear(5,3) print(linear.weight.shape, linear.bias.shape)
torch.matmal, @
torch.add, +
移步vscode,试一试,shape那些事,以及Tensor Broadcasting
试试这段代码
a = torch.randn(2, 2, 4) print(a) b = 20 a = a + b print(a) c = torch.randn(2,4) a = a + c print(c) print(a)
并行运算在深度学习时代非常重要
来源: Introduction to PyTorch Tensors
nn.functional
激活函数(引入非线性)
池化
池化: “粗暴的”降维方法
以分类问题举例
x = torch.ones(5) # input tensor y = torch.zeros(3) # expected output w = torch.randn(5, 3, requires_grad=True) b = torch.randn(3, requires_grad=True) z = torch.matmul(x, w)+b loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
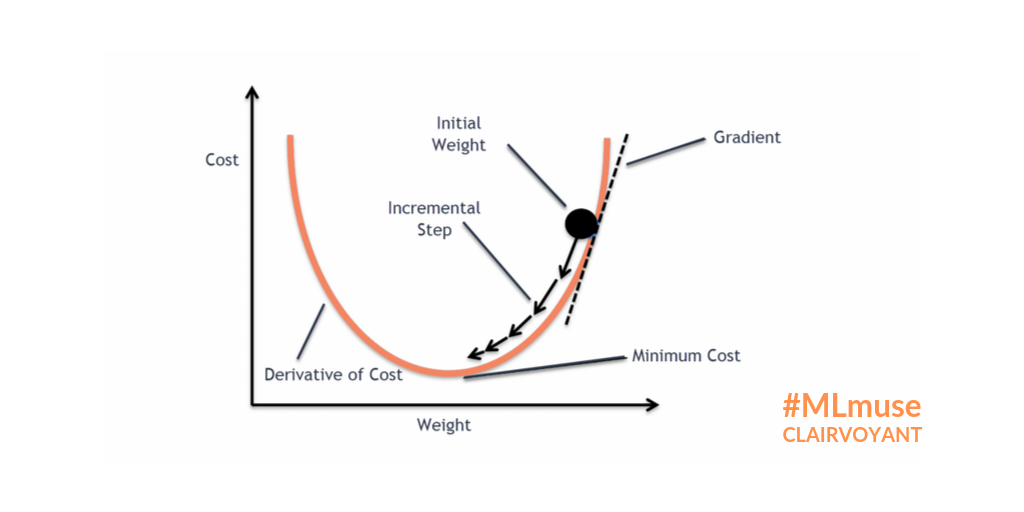
优化目标:
梯度下降法 (Gradient descent): 求偏导
通常以真值(groundtruth)体现,因此重点关注
核心算法: 反向传播(backpropagation)
假设深度学习模型为的复合函数
优化目标的偏导的核心为
链式法则展开:
偏导的构建
“古代”手工实现
autograd
参考阅读
Overview of PyTorch Autograd Engine
How Computational Graphs are Constructed in PyTorch
How Computational Graphs are Executed in PyTorch
目标:
定义损失函数(loss),以及优化器(优化算法)
ce_loss = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
常见损失函数,可在torch.nn中调用
常见优化算法,可在torch.optim中调用
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) model.train() for batch, (X, y) in enumerate(dataloader): pred = model(X) l = loss_fn(pred, y) optimizer.zero_grad() l.backward() optimizer.step() if batch % 100 == 0: loss, current = l.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") return correct
https://marp.app/
--- # PyTorch的动态计算图